最近找工作,发现面试官都会问一个问题:在浏览器输入url之后,会发生什么?
那么,在浏览器输入url之后,到底会发生什么呢?
接下来,我们一起学习一下 ~
主要过程
当我们在浏览器地址栏输入url之后,主要会经过下面几个步骤:
域名解析 –> 发起TCP的3次握手 –> 建立TCP连接后,发起http请求 –> 服务器响应http请求,发送html代码给浏览器 –> (默认)服务器发送html代码后,发起4次挥手,断开TCP请求 –> 浏览器渲染页面
1. 域名解析
域名解析,又叫 DNS解析。用于把地址栏的URL解析成服务器的IP地址,进而访问服务器。
域名解析按优先级,会有以下几种情况:
查询浏览器缓存 :浏览器会缓存之前拿到的DNS 2-30分钟时间,如果没有找到,继续下一种情况;
查询系统缓存 :检查 hosts 文件,这个文件保存了一些以前访问过的网站的域名和IP的数据。它就像一个本地的数据库,如果找到就可以直接获取目标主机的IP地址了。如果没找到,继续下一种情况;
查询路由器缓存 :路由器有自己的DNS缓存,可能包含了需要查询的内容。如果没有,继续下一种情况;
查询ISP DNS 缓存 :ISP服务商的DNS缓存(本地服务器缓存),那里可能有相关的内容。如果还没有,继续下一种情况;
递归查询 :从 根域名服务器 –> 顶级域名服务器 –> 权限域名服务器 –> 得到服务器IP ;
举个(ISP+递归查询)例子,浏览器发起一个DNS的系统调用,首先会先向本地配置的首选DNS服务器(一般是电信运营商提供的,也可以使用像Google提供的DNS服务器)发起域名解析请求。运营商的DNS服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。如果没有找到对应的条目,则由运营商的DNS代我们的浏览器发起迭代的DNS解析请求。
它首先会找一个 根域的DNS的IP地址 ,找到 根域 的地址后,就会向其发起请求(请问 www.linux178.com 这个域名的IP地址是多少啊? ),根域 发现这是一个 顶级域com域 的一个域名,就告诉运营商的DNS我不知道这个域名的IP地址,但我知道 com域 的IP地址,你可以去问它,于是运营商的DNS就得到了 com域 的IP地址,又向 com域 的DNS地址发起了请求(请问 www.linux178.com 这个域名的IP地址是多少啊?),com域 这台服务器告诉运营商DNS,我不知道 www.linux178.com 这个域名的IP地址,但我知道 linxu178.com 这个域的IP地址,你可以去问它,于是运营商的DNS又向 linux178.com 这个域的DNS地址(这个一般就是由域名注册商提供的,像万网、新网等)发送请求(请问 www.linux178.com 这个域名的IP地址是多少啊?),这个时候 linux178.com域 的DNS服务器一查,诶,果然在我这里,于是就把找到的结果返回给运营商的DNS服务器,这个时候运营商的DNS服务器就拿到了 www.linux178.com 这个域名的IP地址了,之后再返回给浏览器,浏览器就得到要访问域名的IP地址了。
2. TCP的三次握手
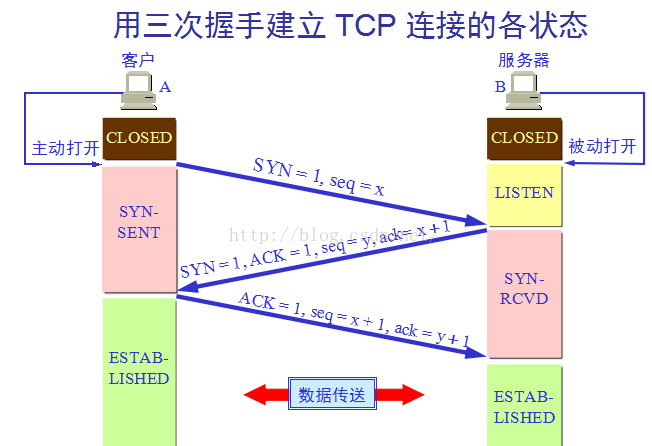
第一次握手 :Client首先发送一个连接试探,ACK=0 表示确认号无效,SYN=1 表示这是一个请求连接或连接接受报文,同时表示这个接受报不能携带数据,seq=x 表示Client自己的初始序号(seq=0 就代表这是第0号包),这时候Client进入 syn_sent ,表示客户端等待服务器的响应;
第二次握手 :Server监听到连接请求报文后,如同意建立连接,则向Client发送确认。TCP报文首部中的 SYN 和 ACK 都置1,ack=x+1 表示期望收到对方下一个报文段的第一个数据字节序号是x+1,同时表明x为止的所有数据都已正确收到(ack=1 其实就是 ack=0+1,也就是期望客户端的第1个包),seq=y 表示Server自己的初始序号(seq=0 就代表这是服务器这边发出的第0号包)。这时服务器进入 syn_rcvd 状态,表示服务器已经收到Client的连接请求,等待Client的确认;
第三次握手 :Client收到确认后还需要再次发送确认,同时携带要发送给Server的数据。ACK=1 表示确认号 ack=y+1 有效(代表收到服务器的第1个包),Client自己的序号seq=x+1(表示这就是我的第一个包,相对于第0个包来说的),一旦收到Client的确认后,这个TCP连接就进入了 Established 状态,就可以发起http请求了。
为什么要3次握手
为了防止已失效的连接请求报文突然又传送到了服务器,进而产生错误。
举个例子:
“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络节点长时间滞留了,以致延误到连接释放以后的某个时间才到达server。这本来是一个早已失效的报文段,但server收到此报文段后,误认为这是client再出发出的一个新的连接请求。于是就像client发出确认报文段,同意建立连接。假设不采用 三次握手 ,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的连接已经建立了,并一直在等待client发来数据。这样,server的很多资源就白白浪费了。采用 三次握手 的方法就可以防止上述现象的发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。
3. 传输数据
HTTP请求报文
一个HTTP请求报文由 请求行(request line) ,请求头部(header) ,空行 ,请求数据 4个部分组成,下图给出了请求报文的一般格式。
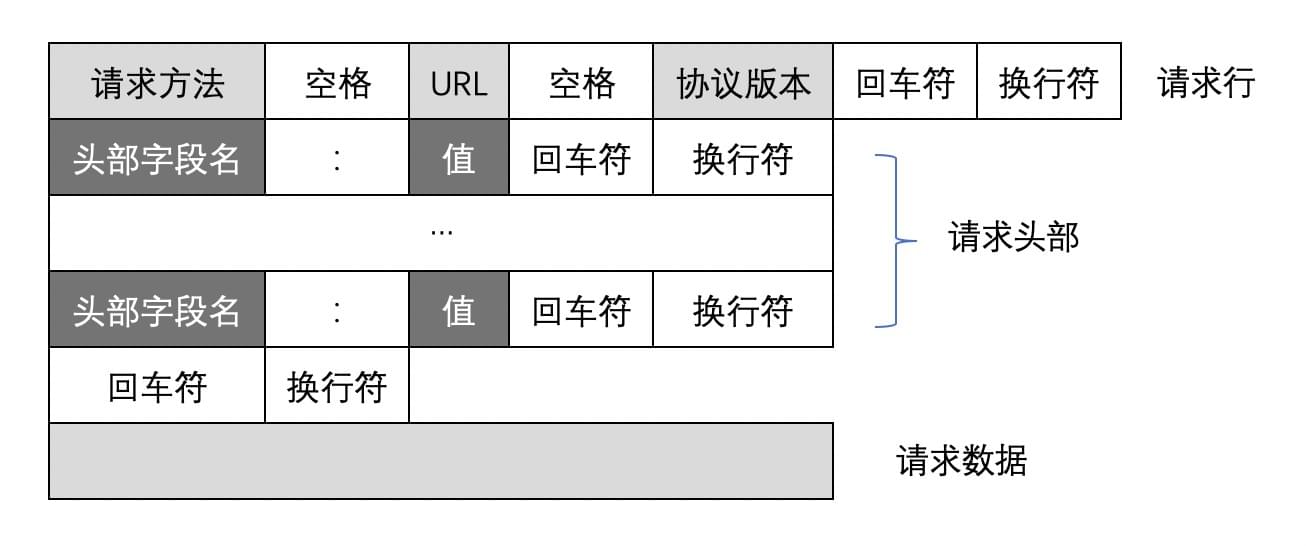
请求行
请求行分为三个部分:请求方法 ,请求地址 和 协议版本 。
请求方法
HTTP/1.1 定义的请求方法有8中:GET、POST、PUT、DELETE、PATCH、HEAD、OPTIONS、TRACE 。
最常用的两种是 GET 和 POST ,如果是 RESTful 接口的话一般会用到 GET、POST、DELETE、PUT 。
请求地址
URL:统一资源定位符,是一种资源位置的抽象唯一识别方法。
组成如下(端口和路径有时可以省略) :

GET 请求时,有时会带参数。
协议版本
协议版本的格式为:HTTP/主版本号.次版本号 ,常用的有 HTTP/1.0 和 HTTP/1.1 。
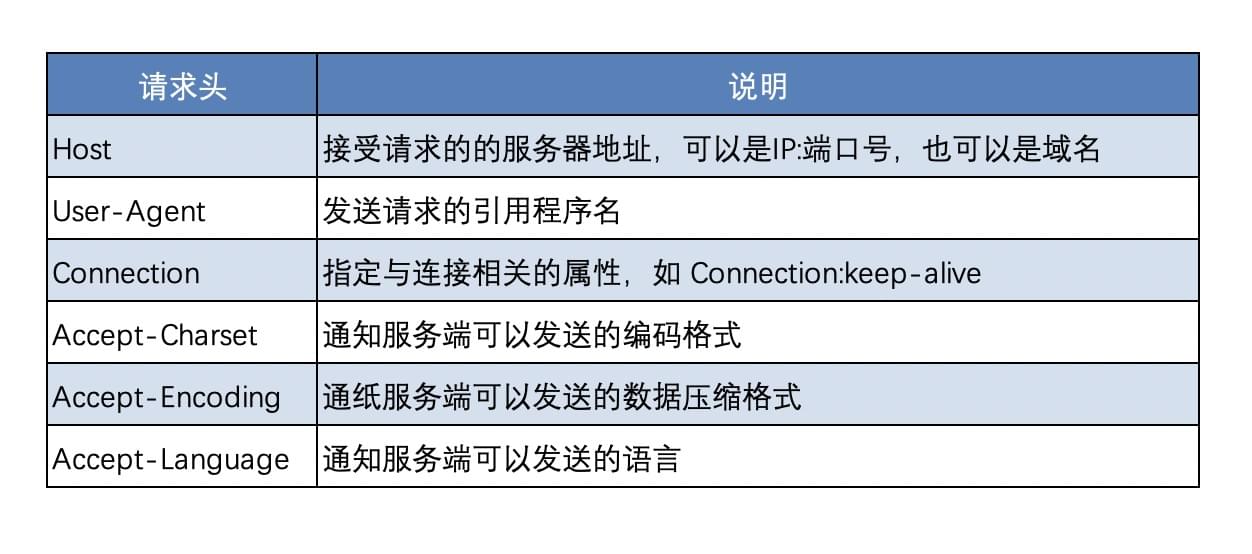
请求头部
请求头部为请求报文添加了一些附加信息,由 名/值 对组成,每行一对,名和值之间用冒号分隔。
常见请求头如下:
请求头部的最后会有一个 空行 ,表示请求头部结束,接下来为请求数据。这一行非常重要,必不可少。
请求数据
可选部分,比如 GET 请求就没有请求数据。
下面是一个 POST 方法的请求报文:
1 | POST /index.php HTTP/1.1 //请求行 |
HTTP响应报文
HTTP响应报文主要由 状态行 ,响应头部 ,空行 和 响应数据 4个部分组成。下图给出了响应报文的一般格式。
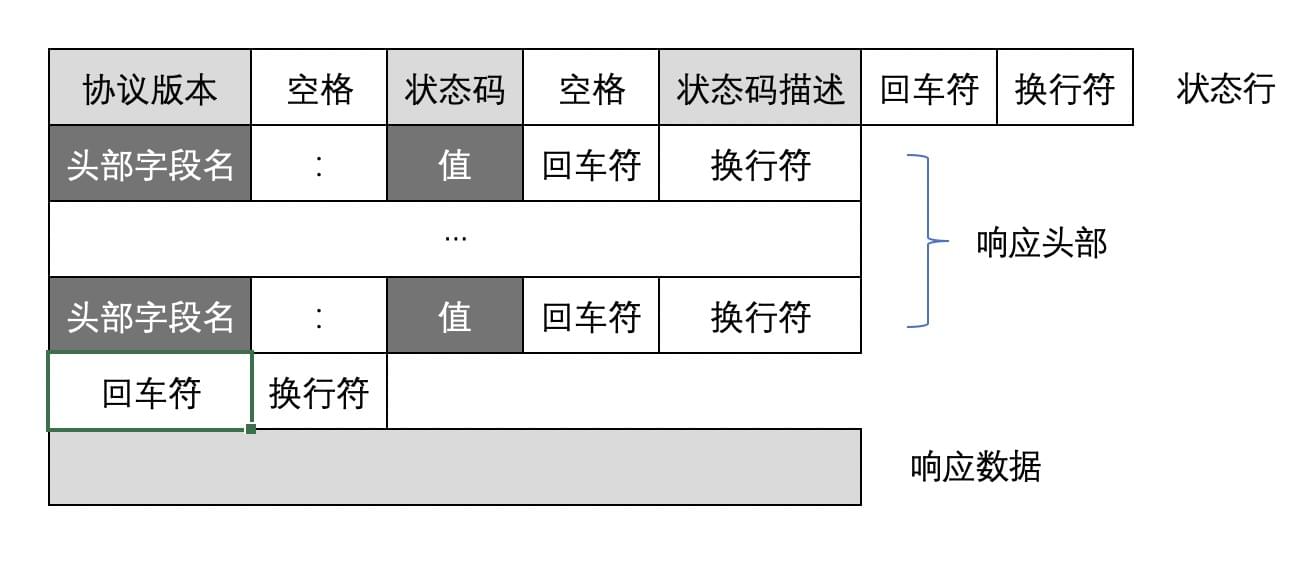
状态行
由3部分组成,分别为:协议版本 ,状态码 ,状态码描述 。
其中 协议版本 和请求报文一致,状态码描述 是对状态码的简单描述,所以这里只介绍 状态码 。
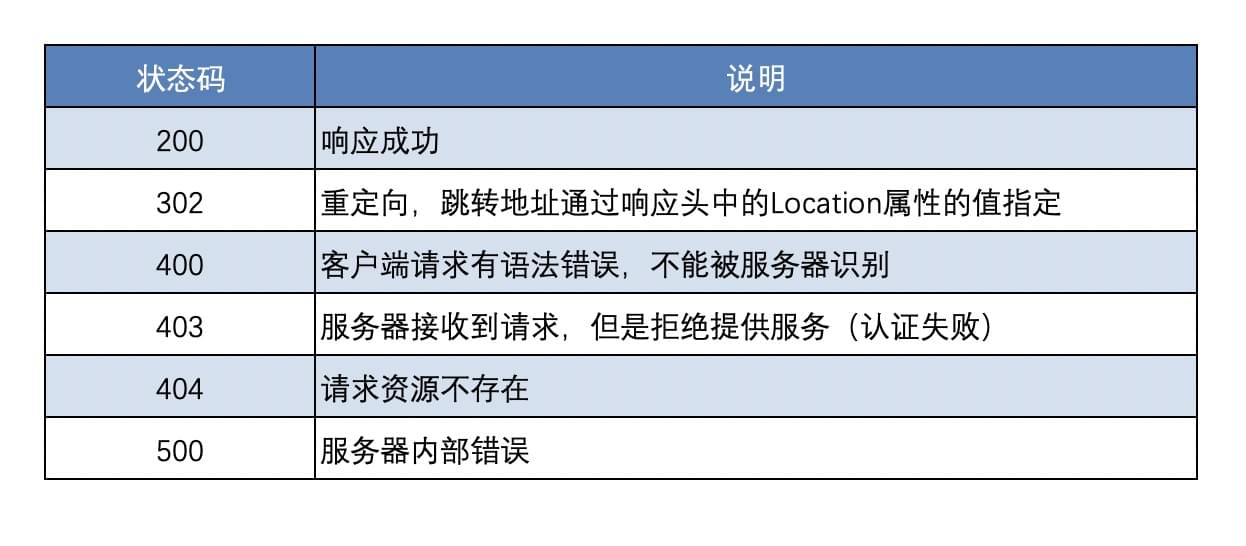
状态码
状态码 为3位数字。
1xx :指示信息——表示请求已接收,继续处理。
2xx :成功——表示请求已被成功接收、理解、接受。
3xx :重定向——表示要完成请求必须进行进一步的操作。
4xx :客户端错误——请求有语法错误或请求无法实现。
5xx :服务器端错误——服务器未能实现合法的请求。
下面列举几个常见的:
响应头部
与 请求头部 类似,为响应报文添加一些附加的信息。
常见的 响应头部 如下:

响应数据
用于存放需要返回给客户端的数据信息。
下面是一个响应报文的实例:
1 | HTTP/1.1 200 OK //状态行 |
4. TCP的四次挥手
默认情况下的TCP连接,在服务器发送一次html数据给浏览器后,服务器就会执行 四次挥手 以 断开TCP连接 ,除了下面这种情况:
持久连接 :只要任意一端没有明确的提出断开连接,则保持TCP连接状态。在 请求首部字段 中设置 Connection:keep-alive 即表示使用了持久连接。
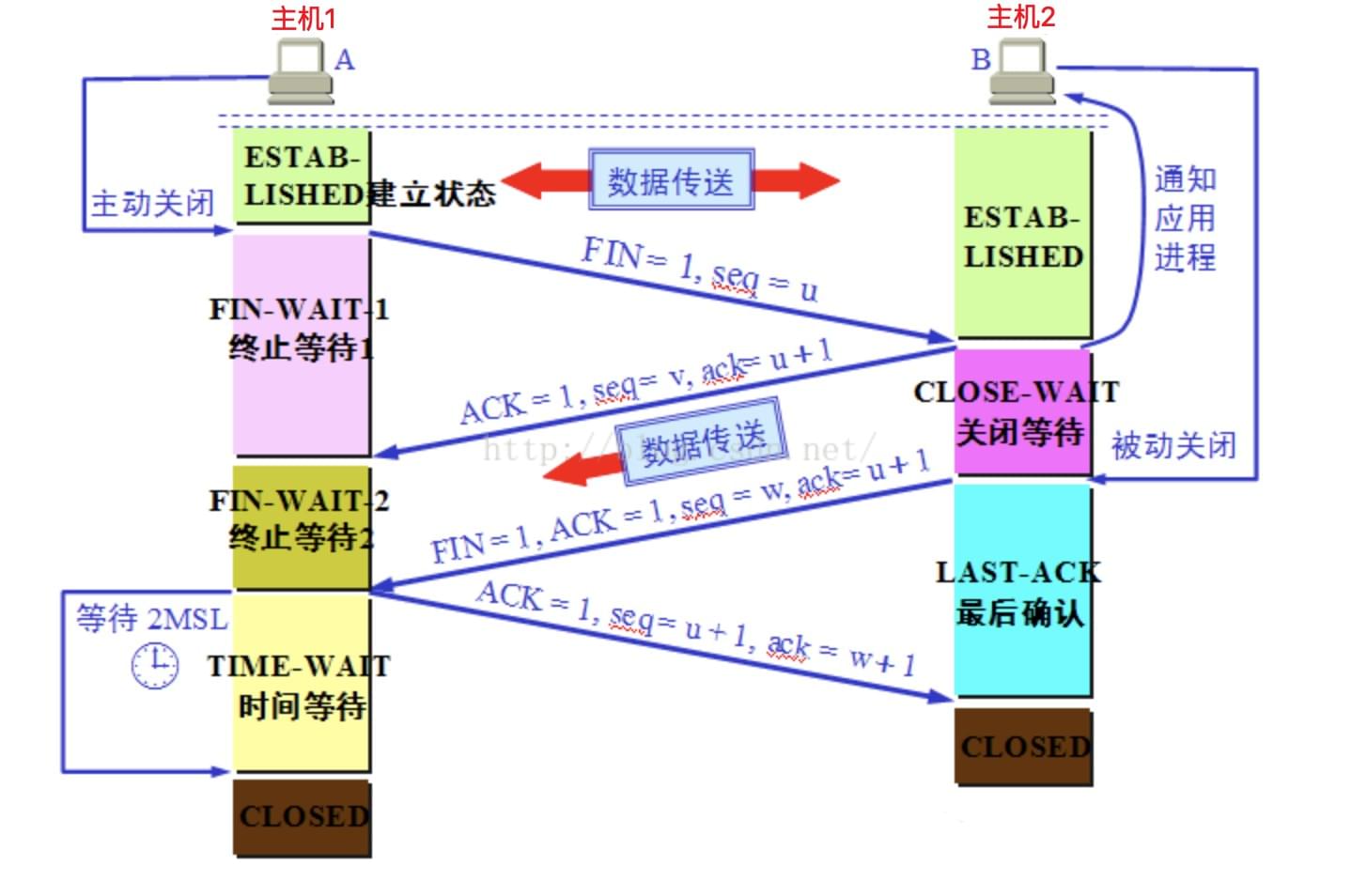
注意 :
- 主机1可以是
客户端,也可以是服务器端; - 默认情况下,主机1是
客户端,即 客户端主动断开连接 的情况 ; - 若
服务器端主动断开连接,则主机1是服务器端;
过程描述 :
主机1进程发出连接释放报文,并停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,主机1进入 FIN-WAIT-1(终止等待1) 状态。TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。主机2收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并带上自己的序列号seq=v,此时,主机2就进入了 CLOSE-WAIT(关闭等待) 状态。主机2通知高层的应用程序,主机1向主机2的方向就释放了,这时候处于半关闭状态,即主机1已经没有数据要发送了,但是主机2若发送数据,主机1仍然要接受。这个状态还要持续一段时间,也就是整个 CLOSE-WAIT 状态持续的时间。主机1收到主机2的确认请求后,此时,主机1就进入 FIN-WAIT-2(终止等待2) 状态,等待主机2发送连接释放报文(在这之前还需要接受主机2发送的最后的数据)。主机2将最后的数据发送完毕后,就向主机1发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,主机2很可能又发送了一些数据,假定此时的序列号为seq=w,此时,主机2就进入了 LAST-ACK(最后确认) 状态,等待主机1的确认。主机1收到主机2的连接释放报文后了,比如发出确认,ACK=1,ack=w+1,而自己的序列号seq=u+1,此时,主机1就进入了 TIME-WAIT(时间等待) 状态。注意此时TCP链接还没有释放,必须经过 2MSL(最长报文段寿命) 的时间后,当主机1撤销相应的TCB后,才进入 CLOSED 状态。主机2只要接收到了主机1发出的确认,就立即进入 CLOSED 状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,主机2结束TCP连接的时间要比主机1早一些。
为什么要四次挥手
因为三次握手时只是建立一个连接,之后才传递数据,在握手时是没有数据传输的,所以3次即可。
而挥手时,主机1 停止向 主机2 传输数据后,主机2 会立刻响应 主机1,先回一个ACK报文,告诉 主机1,”你发的FIN报文我收到了,但只有等我 主机2 的所有报文都发送完毕后,我才能发送FIN报文”,所以挥手的时候 主机2 要分两步,所以挥手需要四次。
为什么要等待 2MSL
因为网络可能不稳定,最后一个 ACK报文有可能会丢失,所以,TIME-WAIT 状态就是用来重发可能丢失的 ACK报文(第四步的报文)。
在四次挥手的过程中,主机2 在 LAST-ACK(最后确认) 状态时,如果没接收到了 主机1 发来的 ACK报文,则不断发送FIN片段。所以 主机1 不能立即关闭,它必须确认 主机2 接收到了该 ACK之后,才关闭连接。所以,主机1 会设置一个计时器,等待 2MSL的时间,如果再次收到FIN,说明之前发送的ACK没有传到 主机2,于是会重新发一个ACK给 主机2;如果等待 2MSL后没有收到FIN,说明 主机2 已收到ACK且已关闭,于是 主机1 也关闭,TCP连接结束。
5. 渲染HTML页面
客户端拿到服务器传输过来的文件后,找到 HTML 和 MIME 文件,通过 MIME 文件,浏览器知道要用页面渲染引擎来处理 HTML 文件。
页面渲染主要有以下几个步骤:
1. 解析html源码,创建一个DOM树
在 DOM 树中,每一个 HTML 标签都有一个对应的节点,并且每一个文本也都会有一个对应的文本节点。
2. 解析CSS代码,计算出最终的样式数据,形成css对象模型CSSOM
首先会忽略非法的CSS代码,然后按 浏览器默认设置——用户设置——外链样式——内联样式——style样式 的顺序进行渲染。
3. 利用DOM和CSSOM构建一个渲染树(rendering tree)
渲染树和 DOM 树有点像,但是是有区别的。
DOM 树完全和 HTML标签一一对应,但是渲染树会忽略掉不需要渲染的元素,比如 head、display:none 的元素等。
而且一大段文本中的每一行在渲染树中都是一个独立的节点。
渲染树中的每一个节点都存储有对应的css属性。
4. 浏览器根据渲染树,直接把页面绘制到屏幕上
注意点
- JS和图片会阻塞 DOM 的加载和渲染。
- CSS不会阻塞 DOM 的加载,但会阻塞 DOM 的渲染(即浏览器控制台可以打印 DOM 节点了,但页面还是空白,没有渲染)。
- CSS会阻塞JS的加载和执行。
- 加载JS时,添加
defer参数,脚本会立即下载但不执行,在 DOM 加载完成后再执行。多个defer的脚本会按顺序执行。 - 加载JS时,添加
async参数,脚本会异步加载再执行,执行的时候还是会阻塞 DOM 的加载。多个async的脚本不会按顺序执行。 - 实际情况下,有时候多个
defer时加载完后不一定会按顺序执行,所以建议,尽量合并成一个JS再使用defer。 - 关于
defer和async,可以查看下图:
